-

Bachelor's

-

Masters
-

MBA
-

Doctorate
-

Micro Credit
-

Explore all Courses
-
Postgraduate Certifications

-
Postgraduate Diploma
-
Undergraduate Diploma
-
Diploma







The Synthetic Data Revolution: Solving Privacy and Data Scarcity in AI Training

Author: pallavi patnaik
|9
MINS READ
| 0
| 259
Created On: 08 April, 2026
Share





Table of Contents (TOC):
- Introduction
- Key Takeaways
- What is Synthetic Data for AI Training?
- Understanding Data Scarcity in Artificial Intelligence
- How Synthetic Data Solves the Data Scarcity Problem
- Types of Synthetic Data
- Synthetic Data Generation Tools and Techniques (2026 Trends)
- Deep Learning with Limited Data: Practical Applications
- Challenges and Limitations of Synthetic Data
- Real-World Case Study
- Trends Defining the Next Phase of Synthetic Data
- Conclusion
- FAQs
Introduction
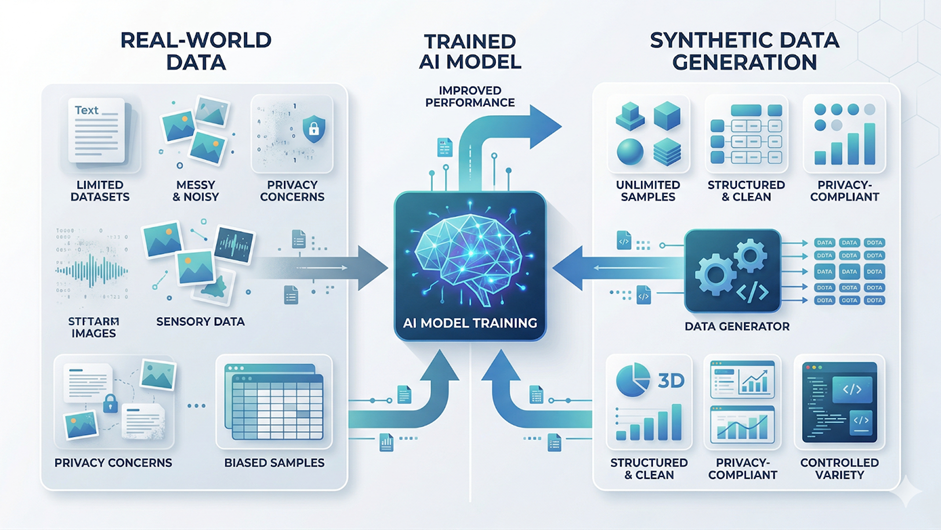
Let us imagine building a powerful AI system, but not having enough data to train it effectively.
This is no longer hypothetical. As artificial intelligence expands across industries, data scarcity in artificial intelligence has become a major challenge. High-quality datasets are often limited, expensive, or restricted due to privacy regulations, especially in sectors like healthcare, finance, and education.
At the same time, modern AI systems, particularly deep learning models, require large volumes of data. Without it, models may struggle with overfitting, bias, and poor generalization.
This is where synthetic data for AI training is transforming AI development.
Instead of relying entirely on real-world datasets, organizations can generate artificial data that mimics real-world patterns. This enables scalable, privacy-safe data creation on demand.
By addressing both the data scarcity problem and privacy concerns, synthetic data is enabling faster experimentation and more robust AI systems.
Key Takeaways:
- Synthetic data is emerging as a powerful solution to the data scarcity problem in AI
- It enables deep learning with limited data while preserving privacy.
- Advanced synthetic data generation tools in 2026 use generative AI and diffusion models
- Synthetic data improves scalability but still comes with limitations and risks
- It is becoming essential across industries like healthcare, fintech, and education.
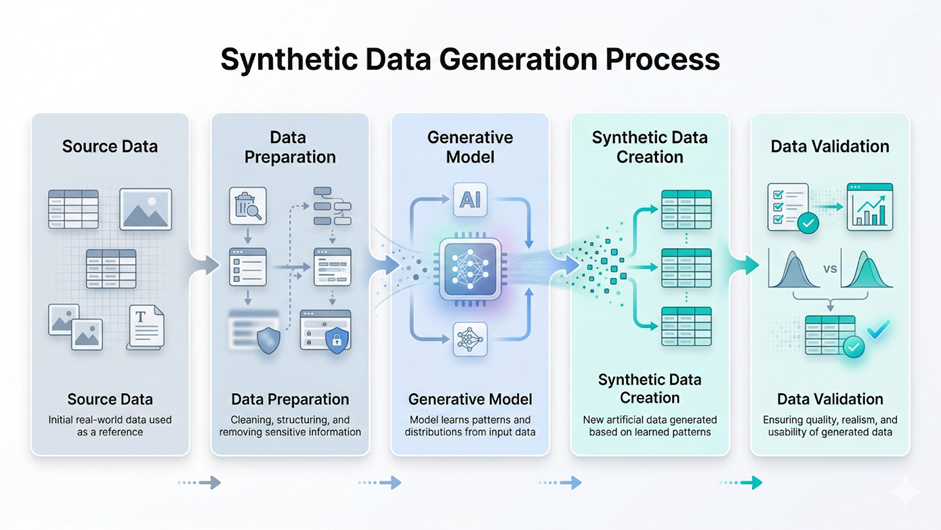
What is Synthetic Data for AI Training?
Synthetic data refers to artificially generated data that is designed to closely replicate the statistical properties of real-world data. Instead of collecting information from actual users or environments, this data is created using algorithms that model real-world patterns, relationships, and distributions.
Key Characteristics
Synthetic data does not contain real user information, making it suitable for privacy-sensitive use cases. At the same time, it preserves patterns and relationships from real datasets, allowing effective model training. It is also highly scalable, as large volumes can be generated on demand without traditional data collection constraints.
Why It Matters
The value of synthetic data for AI training lies in enabling safe and efficient model development. It removes privacy risks, reduces dependence on costly or limited real-world data, and allows faster experimentation. This helps improve model performance and scalability.
This is why synthetic training data is becoming a core component of modern AI pipelines.
Understanding Data Scarcity in Artificial Intelligence
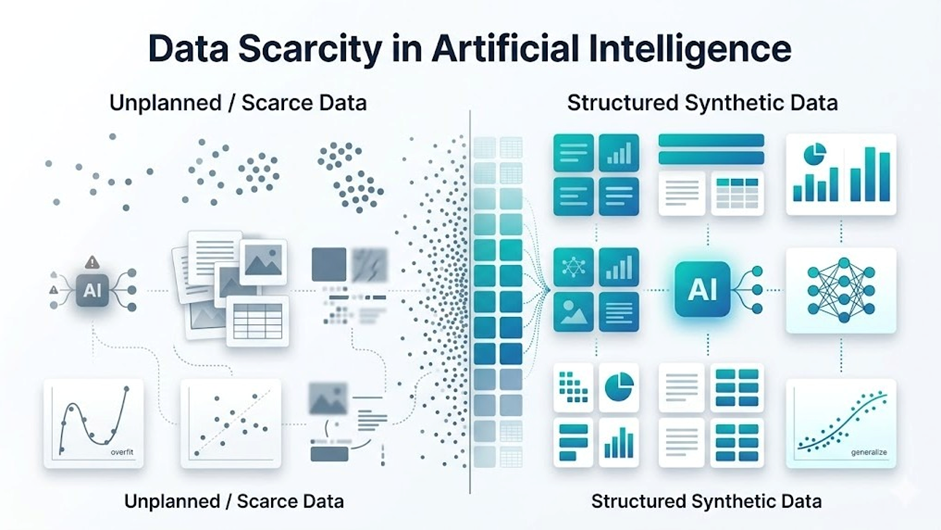
What is Data Scarcity?
Data scarcity in AI refers to situations where training data is limited, unreliable, or inaccessible. In many cases, datasets are too small, biased, or incomplete to capture meaningful patterns. Even when data exists, strict privacy regulations often restrict its use, leading to inaccurate predictions. In other cases, even when data exists, it cannot be freely used due to strict privacy regulations.
Why Does Data Scarcity Occur?
Key reasons include data protection laws like GDPR and HIPAA, which limit access to sensitive data. Data collection is also costly and time-consuming. Additionally, rare events, such as fraud or certain medical conditions, naturally result in limited datasets.
What is the Impact on AI Models?
Data scarcity reduces model accuracy and can lead to overfitting, where models fail in real-world scenarios. It also affects generalization, making models less reliable when handling new or unseen data.
How Synthetic Data Solves the Data Scarcity Problem
Synthetic data directly addresses the data scarcity problem by enabling more flexible and efficient data usage.
Data Augmentation at Scale
Synthetic data allows teams to generate large volumes of data quickly, creating multiple variations of existing datasets. This helps improve model robustness and performance without relying on additional real-world data.
Privacy Preservation
Since synthetic data does not include real personal information, it ensures privacy and compliance. This makes it especially useful in sensitive domains like healthcare and finance.
Balanced Datasets
It helps correct class imbalance by generating data for rare cases, such as fraud detection or uncommon medical conditions, leading to more accurate and fair models.
Faster Model Development
With on-demand data generation, teams no longer need to wait for data collection. This speeds up experimentation and accelerates the overall AI development process.
Together, these capabilities make synthetic data in machine learning a practical and scalable solution to the data scarcity problem.
Types of Synthetic Data
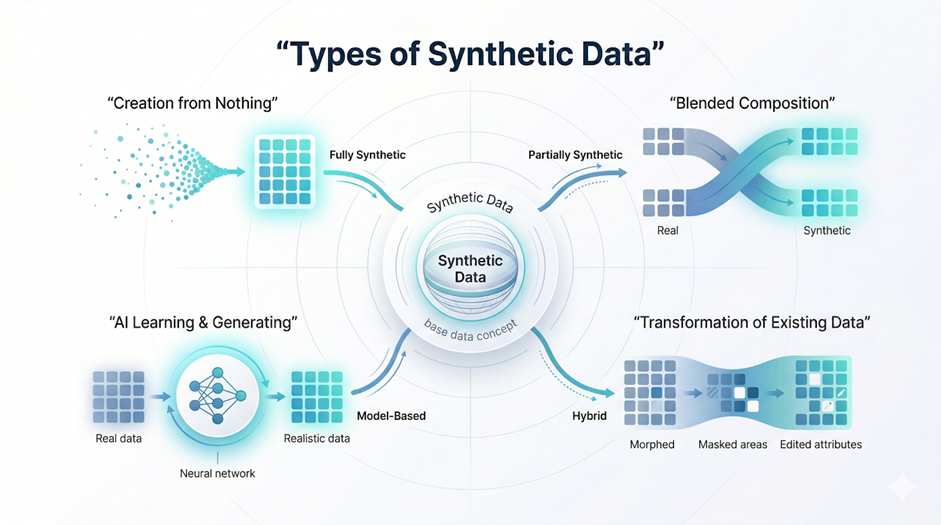
Understanding the types of synthetic data is important, as each type is designed for different use cases based on privacy needs and accuracy requirements.
Fully Synthetic Data
In this approach, the entire dataset is artificially generated without using any real data. It offers the highest level of privacy and is commonly used in highly sensitive applications.
Partially Synthetic Data
This type combines real data with generated data. While some original information is retained, synthetic elements are added to enhance the dataset and improve usability.
Hybrid Data
Hybrid data involves modifying real datasets using AI techniques. It keeps the core structure of real data while transforming certain attributes to ensure privacy and flexibility.
Generative Model-Based Data
This type is created using advanced models like GANs, VAEs, and diffusion models, which learn patterns from real data and generate highly realistic synthetic datasets.
Each of these types plays a specific role in synthetic data generation, depending on how privacy, realism, and scalability need to be balanced.
Synthetic Data Generation Tools and Techniques (2026 Trends)
The evolution of synthetic data generation tools in 2026 is largely driven by advancements in generative AI, making data creation faster, smarter, and more accessible across industries.
Popular Techniques
Modern synthetic data generation relies on advanced models such as Generative Adversarial Networks (GANs), diffusion models—which have emerged as a leading trend in 2026—and Variational Autoencoders (VAEs). These techniques enable the creation of highly realistic data by learning complex patterns from existing datasets.
Leading Synthetic Data Generation Tools
Today’s tools are increasingly powered by foundation models and are seamlessly integrated into enterprise AI pipelines. Many platforms also offer no-code interfaces, allowing even non-technical users to generate and work with synthetic data efficiently.
2026 Trend Highlight
A key shift in 2026 is the use of AI agents that can automatically generate, refine, and validate synthetic datasets with minimal human intervention. Additionally, real-time synthetic data generation is gaining traction, especially in simulation-based environments where continuous data flow is required.
Also Read: Machine Learning vs Artificial Intelligence
Deep Learning with Limited Data: Practical Applications
Synthetic data plays a key role in enabling deep learning with limited data, especially when large, high-quality datasets are difficult to obtain. By generating realistic and diverse data, it helps models learn better patterns and improve performance across domains.
Healthcare
In healthcare, synthetic data is used to simulate patient records, medical images, and clinical scenarios. This enables training of diagnostic models without exposing sensitive data, while also improving dataset diversity and reliability.
Finance
In finance, it supports fraud detection and risk analysis by generating rare-event scenarios. This helps models identify unusual patterns more effectively and improves detection accuracy.
Autonomous Systems
For autonomous systems, synthetic data creates simulated environments with varied conditions like weather and traffic. This allows models to learn safely and handle complex real-world situations before deployment.
Education
In EdTech, synthetic data simulates student behavior and performance, enabling personalized learning paths and adaptive testing even when real data is limited.
Also Read: Explainable AI: Decoding the Black Box of Machine Decisions
Challenges and Limitations of Synthetic Data
While synthetic data offers significant advantages, it also comes with certain limitations that need to be carefully managed.
Data Quality Issues
The effectiveness of synthetic data depends heavily on how it is generated. If the underlying models or assumptions are weak, the generated data may not accurately reflect real-world patterns. This can mislead AI models and reduce their performance.
Bias Replication
Synthetic data is often created based on existing datasets. If those original datasets contain biases, the synthetic data may replicate or even amplify those biases, leading to unfair or inaccurate outcomes.
Lack of Real-World Complexity
Although synthetic data can simulate many scenarios, it may still miss the unpredictability and complexity of real-world environments. As a result, models trained only on synthetic data may struggle when exposed to real-world situations.
Validation Challenges
Evaluating the quality and authenticity of synthetic data is not always straightforward. It can be difficult to measure how closely the generated data matches real-world conditions, making validation a key challenge.
Also Read: From Morning to Night: 10 Ways AI Is Part of Your Daily Routine
Real-World Case Study
Let us take a closer look at how synthetic data has been applied in a real-world, research-backed scenario.
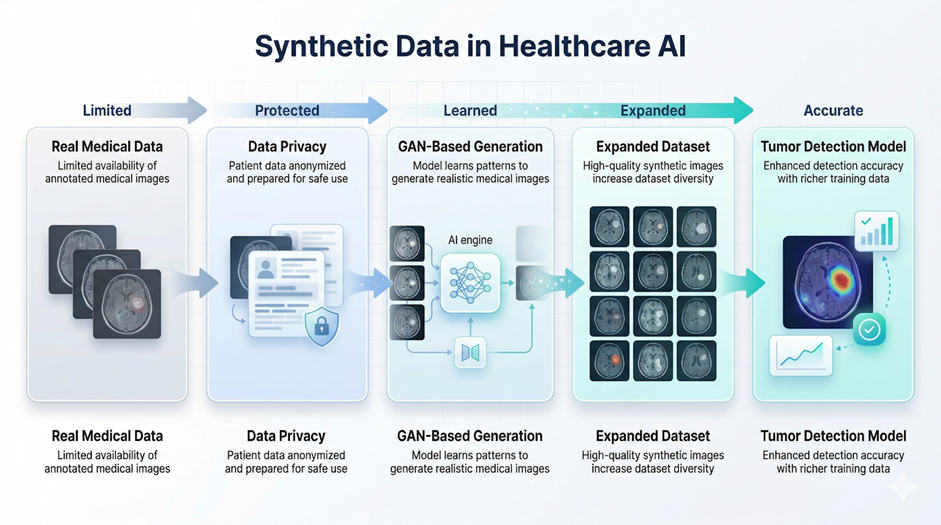
Healthcare AI GAN-Based Synthetic Medical Image Augmentation for Tumor Detection
One well-documented use of synthetic data comes from medical imaging, particularly in cancer detection. Researchers have used Generative Adversarial Networks (GANs) to generate synthetic MRI and CT scan images for training AI models.
In studies such as GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification, synthetic images were used to augment limited datasets of tumor scans. Since real medical data is often scarce and highly regulated, this approach allows researchers to expand training datasets without compromising patient privacy.
By combining real and synthetic images, these models can learn from a wider range of scenarios, improving their ability to detect tumors, especially in early-stage cases. The added variability makes models more robust and better at generalizing to new data.
Importantly, these studies show that models trained with synthetic data perform better than those trained on small real datasets alone, while still maintaining compliance with strict healthcare data regulations.
This example clearly demonstrates how synthetic data for AI training is not just theoretical—it is already being validated through real-world research.
Trends Defining the Next Phase of Synthetic Data
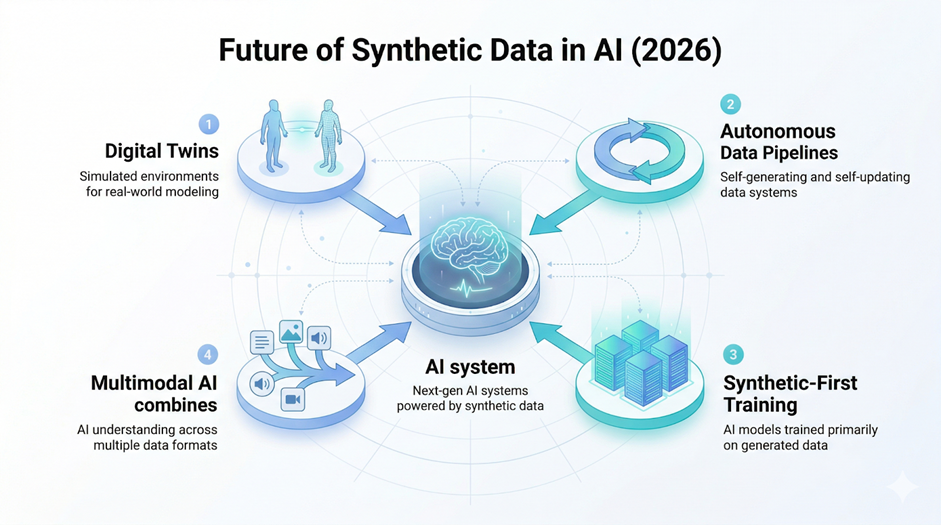
The future of synthetic data in AI is evolving rapidly, driven by advancements in generative technologies and the need for scalable, privacy-safe data.
Emerging Trends
AI-generated digital twins are enabling realistic simulations of real-world systems for training and testing. At the same time, organizations are adopting autonomous data pipelines, where AI can generate, refine, and validate datasets with minimal human input.
Another key shift is synthetic-first training, where models are initially trained on synthetic data and later fine-tuned using real data. The integration of synthetic data with multimodal AI, combining text, images, and video, is also expanding AI capabilities.
By 2026, synthetic data is moving from an alternative to a default approach, fundamentally redefining how AI systems are trained and scaled.
Also Read: What Are the Top 5 AI Skills to Learn
Conclusion
The rise of synthetic data for AI training is reshaping how modern AI systems are designed and developed.
It offers a practical solution to data scarcity in artificial intelligence, while also enabling privacy-safe innovation and more scalable model development. By reducing dependence on real-world datasets, synthetic data is helping organizations move faster and experiment more effectively. At the same time, its true value lies in how it is used. Combining synthetic data with real data remains essential to ensure accuracy, fairness, and reliable performance in real-world applications.
As AI continues to evolve, synthetic data is not just supporting progress— it is becoming a foundational element in shaping the next generation of intelligent systems.
FAQs
Q1. What is synthetic data in machine learning?
A: Synthetic data is artificially generated data that mimics real-world datasets and is used to train AI models.
Q2. How does synthetic data solve data scarcity?
A: It generates large volumes of training data, helping overcome the data scarcity problem without relying on real-world datasets.
Q3. Is synthetic data better than real data?
A: Not entirely. It is best used alongside real data to improve performance and scalability.
Q4. What are common synthetic data generation tools?
A: Modern tools use GANs, diffusion models, and AI-driven automation for generating realistic datasets.
Q5. What are the risks of synthetic data?
A: Key risks include bias replication, unrealistic patterns, and validation challenges.
Explore Related Courses














COMMENTS(0)
Explore Related Courses
Our Popular Insights
Careers are shifting faster than ever, and staying relevant takes more than experience. Explore UniAthena’s most-read blogs for sharp insights, emerging skills, and practical pathways that help you move forward with clarity and confidence in a changing professional world.


How to Switch Career to Data Analytics?
Read More
6
mins read





How to Switch Career to Data Analytics?
Read more
6
mins read

Get in Touch

It’s Time to Start
Join NowMost Popular Online Specialization
- Master of International Business Administration
- Master of Business Administration
- MBA in General Management- FastTrack
- Master in Innovation and Entrepreneurship
- MBA-Family Business Management
- Master in Procurement and Contract Management
- Extended Diploma in Business Analytics (SCQF Level 11)
- Diploma in Supply Chain and Logistics Management (SCQF Level 11)
- Strategic Human Resource Management Practitioner
- Master in Data Science
- Master in Engineering Management
Trending Online
- Integrated Doctorate of Business Administration
- Postgraduate Certificate in Finance for Next Generation Managers
- Master of Business Administration- General Management (Fast Track)
- Postgraduate Certificate in Socio-Economic and Legal Framework
- Postgraduate Certificate in Business Sustainability
- Certified Manager
- Supply Chain Management Practitioner
- MBA - AI in Business
- MBA - Accounting & Finance
- Master in Supply Chain and Logistics Management
Top Universities Online Certificates
- Postgraduate Certificate in International Marketing Management
- Postgraduate Certificate In International Human Resource Management
- Postgraduate Certificate in Strategic Management
- Postgraduate Certificate in Procurement & Contracts Management
- Postgraduate Certificate in Business Analytics
- Postgraduate Certificate in Strategic Supply Chain & Logistics Management
- Postgraduate Certificate in Human Resource and Leadership
- Project Management Practitioner
- Postgraduate Certificate in Supply Chain Design & Implementation
- Postgraduate Certificate in Management Accounting and Finance
Accredited Online Degree Program
- MBA - Digital Transformation
- MBA - Family Business Management
- MBA - Marketing Management
- MBA in Quality Management
- MBA - Business Intelligence & Data Analytics
- MBA in Operations & Project Management
- MBA in Energy Management
- MBA In Construction & Safety Management
- Master in Organisational Leadership
- Master in Public Health
- Master in Construction Management
- Bachelor of Arts in Business Administration



UniAthena is an Ed-Tech, offering flexible, affordable learning solutions, including Free-Learning Upskilling Courses and Academic Programs in partnerships with accredited and globally renowned universities and professional qualification bodies.




Do you have any questions ?
Feel free to send us your questions or request a free consultation
Send a messageUK
Athena Global Education
Magdalen Centre,
Robert Robinson Avenue,
Oxford, OX4 4GA, UK
Phone : 01865 784299
MIDDLE EAST
Athena Global Education FZE
Block L-03, First Floor,
P O Box 519265, Sharjah Publishing City,
Free Zone, Sharjah, UAE
Phone : +971 55 879 5492
INDIA
Uniathena Private Limited
9A,Midas Tower
Phase 1
Hinjewadi Rajiv Gandhi Infotech Park
Pune-411057
Phone: +91 9145665544
All Copyrights Reserved @ Athena Global Education 2021-2026