-

Bachelor's

-

Masters
-

MBA
-

Doctorate
-

Micro Credit
-

Explore all Courses
-
Postgraduate Certifications

-
Postgraduate Diploma
-
Undergraduate Diploma
-
Diploma







The Privacy-Safe Way to Train AI: A Guide to Synthetic Data

Author: malik basit ahmad
|4
MINS READ
| 0
| 198
Created On: 28 January, 2026
Share





Table of Contents (TOC):
- Introduction
- Key Takeaways
- What is Synthetic Data Generation?
- What is a Synthetic Dataset?
- How is Synthetic Data Generated?
- Synthetic Data Generation Methods
- Synthetic Data Generation Algorithms
- How to Generate Synthetic Data (Step-by-Step)
- Synthetic Data Generation Tools
- Synthetic Data Generator Python (Example)
- Synthetic Data vs Real Data
- Is Synthetic Data Reliable?
- Synthetic Data Use Cases
- Synthetic Data Example
- Final Thoughts
- FAQ Section
Introduction
Is it possible to create powerful AI models without collecting sensitive personal data or waiting many years to collect such large datasets?
This is where synthetic data generation becomes important.
As AI systems become ever more sophisticated, companies are turning to AI synthetic data to solve common problems such as privacy risks, data shortages, and hidden bias in real datasets. Still, several key questions remain:
- What is synthetic data generation?
- How is synthetic data generated?
- And most importantly, is synthetic data reliable?
In this blog, we’ll answer all of these questions in simple English, with clear examples, tools, and real-world use cases.
Key Takeaways:
- Synthetic data is artificial data that behaves like real data but doesn’t expose real people.
- AI synthetic data helps train machine learning models safely.
- It’s widely used in healthcare, finance, autonomous vehicles, and AI research.
- There are many synthetic data generation methods, from basic rules to deep learning.
- Reliability depends on how well the synthetic data reflects real-world patterns.
What is Synthetic Data Generation?
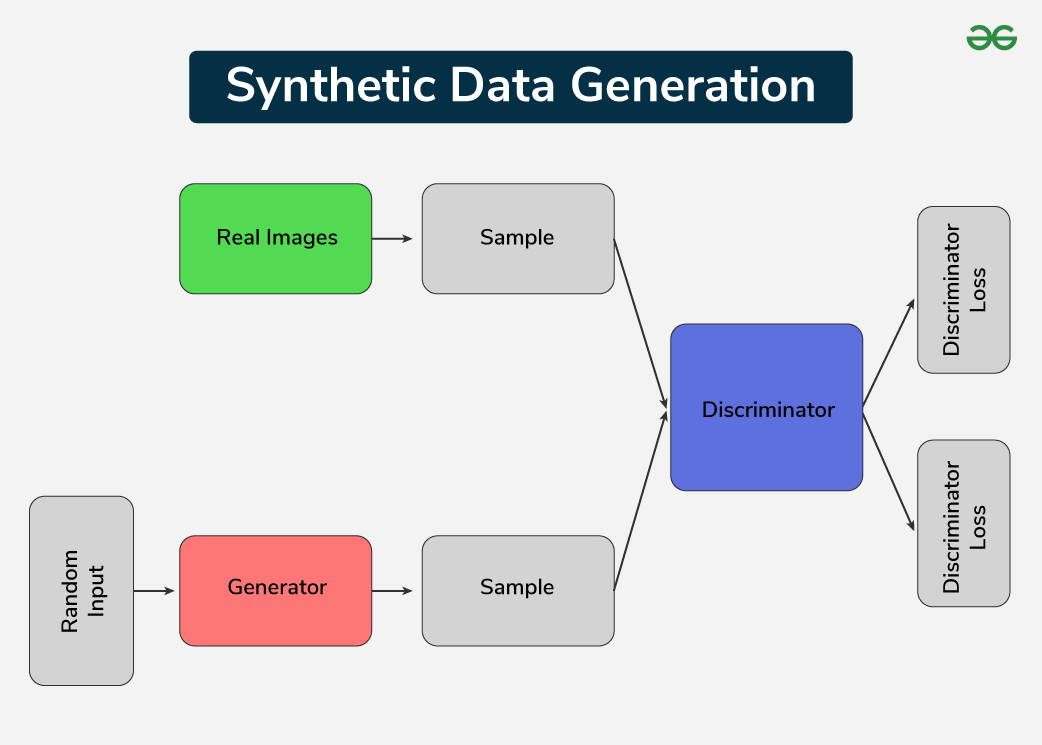
Source: Synthetic Data Generation
Synthetic data generation is the process of creating artificial data that looks and behaves like real-world data—without using actual personal or sensitive information.
Instead of copying real records, synthetic data simulates patterns, such as trends, relationships, and distributions.
In simple terms:
- It looks real
- It acts real
- But it doesn’t belong to real people
That’s why synthetic data is becoming a foundation of modern AI development.
What is a Synthetic Dataset?
A synthetic dataset is a collection of artificially created data points that mirror real data.
Key characteristics:
- No direct connection to real individuals
- Preserves trends, patterns, and correlations
- Safe to use for training, testing, and simulations
How is Synthetic Data Generated?
To understand how synthetic data is generated, think of it as a learning-and-copying process—without copying real data.
At a high level:
- Real data patterns are studied
- Mathematical or AI models learn those patterns
- New artificial data points are generated based on what the model learned
Synthetic Data Generation Methods
Some commonly used synthetic data generation methods include:
- Rule-based generation:
Uses predefined rules and constraints - Statistical modeling:
Data is generated using probability distributions. - Agent-based simulation:
Simulates real-world behavior over time - Machine learning-based generation:
Learns patterns directly from data - Deep learning approaches:
Uses advanced models like GANs and VAEs
Synthetic Data Generation Algorithms
Popular synthetic data generation algorithms include:
- Generative Adversarial Networks (GANs)
- Variational Autoencoders (VAEs)
- Bayesian Networks
- Markov Chain Models
- Copula-based models
Each algorithm differs in realism, complexity, and computing cost.
How to Generate Synthetic Data (Step-by-Step)
Here’s a simple step-by-step workflow:
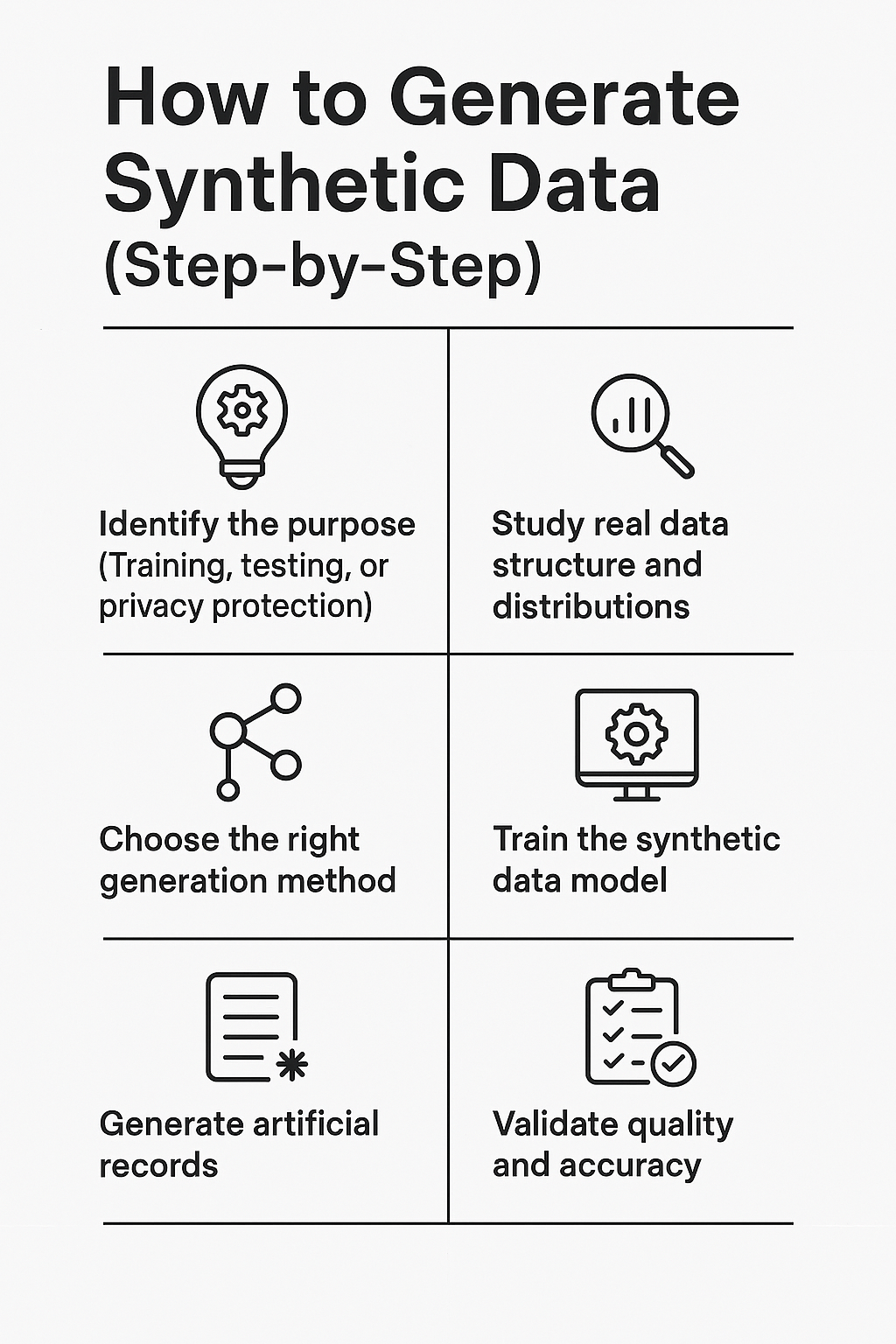
Synthetic Data Generation Tools
Some popular synthetic data generation tools include:
- AI platforms with built-in data generators
- Open-source Python libraries
- Enterprise-level data simulators
- Cloud-based synthetic data solutions
These tools make large-scale synthetic data creation faster and easier.
Also Read: Generative AI Vs AI Agents Vs Agentic AI: What’s the Difference?
Synthetic Data Generator Python (Simple Example)
Python is one of the most popular languages for synthetic data creation.
A typical synthetic data generator Python workflow uses:
- NumPy and Pandas for statistical data
- Scikit-learn for modeling
- Deep learning libraries for GAN-based data
Python makes synthetic data accessible—even for beginners.
Synthetic Data vs Real Data
This comparison explains why synthetic data vs real data is such an important discussion today.
Is Synthetic Data Reliable?
So, is synthetic data reliable?
Yes—when it’s generated properly.
Reliability depends on:
- How well real data patterns are captured
- The generation method used
- Proper validation against real benchmarks
Poorly generated synthetic data can mislead models, but high-quality AI synthetic data can perform almost as well as real data.
Synthetic Data Use Cases
Common synthetic data use cases include:
- Training AI models safely
- Sharing healthcare data securely
- Financial fraud detection
- Autonomous vehicle simulations
- Software testing and QA
- Data augmentation for machine learning
Synthetic Data Example
A simple synthetic data example:
- Generate thousands of fake customer transactions
- Maintain realistic spending patterns
- Ensure no real customer information is exposed
This allows companies to experiment and innovate without privacy risks.
Final Thoughts
Synthetic data generation is not a future idea—it’s already here.
With improvements in AI synthetic data, organizations can build better models while staying ethical and compliant. While synthetic data may not fully replace real data, it works extremely well as a powerful companion.
As tools and algorithms continue to improve, the gap between synthetic and real data will keep shrinking.
FAQs
Q1. What is synthetic data generation used for?
A: To train AI models, protect privacy, test systems, and simulate real-world scenarios.
Q2. How is synthetic data generated in AI?
A: AI models learn patterns from real data and generate new artificial data with similar behavior.
Q3. Is synthetic data better than real data?
A: Not always better—but often safer, cheaper, and more scalable.
Q4. Can synthetic data replace real data completely?
A: In some cases, yes, but most applications benefit from a hybrid approach.
References:
Explore Related Courses














COMMENTS(0)
Explore Related Courses
Our Popular Insights
Careers are shifting faster than ever, and staying relevant takes more than experience. Explore UniAthena’s most-read blogs for sharp insights, emerging skills, and practical pathways that help you move forward with clarity and confidence in a changing professional world.



🌟 Top Project Performer – June 2026 🌟
Read More
1
mins read



🌟 Top Project Performer – May 2026 🌟
Read More
1
mins read
Best AI Tools for Content Creation
Read More
9
mins read

How to Start Freelancing With No Experience
Read More
8
mins read

🌟 Top Project Performer – April 2026 🌟
Read More
1
mins read
🌟 Top Project Performer – June 2026 🌟
Read more
1
mins read
🌟 Top Project Performer – May 2026 🌟
Read more
1
mins read
Best AI Tools for Content Creation
Read more
9
mins read
How to Start Freelancing With No Experience
Read more
8
mins read
🌟 Top Project Performer – April 2026 🌟
Read more
1
mins read
Get in Touch

It’s Time to Start
Join NowMost Popular Online Specialization
- Master of International Business Administration
- Master of Business Administration
- MBA in General Management- FastTrack
- Master in Innovation and Entrepreneurship
- MBA-Family Business Management
- Master in Procurement and Contract Management
- Extended Diploma in Business Analytics (SCQF Level 11)
- Diploma in Supply Chain and Logistics Management (SCQF Level 11)
- Strategic Human Resource Management Practitioner
- Master in Data Science
- Master in Engineering Management
Trending Online
- Integrated Doctorate of Business Administration
- Postgraduate Certificate in Finance for Next Generation Managers
- Master of Business Administration- General Management (Fast Track)
- Postgraduate Certificate in Socio-Economic and Legal Framework
- Postgraduate Certificate in Business Sustainability
- Certified Manager
- Supply Chain Management Practitioner
- MBA - AI in Business
- MBA - Accounting & Finance
- Master in Supply Chain and Logistics Management
Top Universities Online Certificates
- Postgraduate Certificate in International Marketing Management
- Postgraduate Certificate In International Human Resource Management
- Postgraduate Certificate in Strategic Management
- Postgraduate Certificate in Procurement & Contracts Management
- Postgraduate Certificate in Business Analytics
- Postgraduate Certificate in Strategic Supply Chain & Logistics Management
- Postgraduate Certificate in Human Resource and Leadership
- Project Management Practitioner
- Postgraduate Certificate in Supply Chain Design & Implementation
- Postgraduate Certificate in Management Accounting and Finance
Accredited Online Degree Program
- MBA - Digital Transformation
- MBA - Family Business Management
- MBA - Marketing Management
- MBA in Quality Management
- MBA - Business Intelligence & Data Analytics
- MBA in Operations & Project Management
- MBA in Energy Management
- MBA In Construction & Safety Management
- Master in Organisational Leadership
- Master in Public Health
- Master in Construction Management
- Bachelor of Arts in Business Administration


{kind=link}

UniAthena is an Ed-Tech, offering flexible, affordable learning solutions, including Free-Learning Upskilling Courses and Academic Programs in partnerships with accredited and globally renowned universities and professional qualification bodies.




Do you have any questions ?
Feel free to send us your questions or request a free consultation
Send a messageUK
Athena Global Education
Magdalen Centre,
Robert Robinson Avenue,
Oxford, OX4 4GA, UK
Phone : 01865 784299
MIDDLE EAST
Athena Global Education FZE
Block L-03, First Floor,
P O Box 519265, Sharjah Publishing City,
Free Zone, Sharjah, UAE
Phone : +971 55 879 5492
INDIA
Uniathena Private Limited
9A,Midas Tower
Phase 1
Hinjewadi Rajiv Gandhi Infotech Park
Pune-411057
Phone: +91 9145665544
All Copyrights Reserved @ Athena Global Education 2021-2026