-

Bachelor's

-

Masters
-

MBA
-

Doctorate
-

Micro Credit
-

Explore all Courses
-
Postgraduate Certifications

-
Postgraduate Diploma
-
Undergraduate Diploma
-
Diploma







What is RLHF in AI, and How Does It Work?

Author: neha mondal
|5
MINS READ
| 0
| 381
Created On: 08 January, 2026
Share





Have you ever found yourself wondering why AI-powered chatbots are so remarkably human in their replies? The answer is a powerful fine-tuning technique known as Reinforcement Learning through Human Feedback (RLHF).
This groundbreaking approach has revolutionised how large language models (LLMs) are trained, making them more helpful, accurate, safe, and aligned with human values.

Defining RLHF
RLHF stands for Reinforcement Learning from Human Feedback. It is a machine learning process that refines AI models by directly adding human preferences to them. In contrast to the conventional forms of training, which are based only on an automated matrix, RLHF involves real human evaluators who help to direct the model in generating more desirable outputs.
What is Reinforcement Learning?
It is important to understand what reinforcement learning is before delving into RLHF. Reinforcement learning is a type of machine learning in which an agent receives rewards or penalties depending on its actions as it learns to make decisions.
Imagine a dog being trained. When the dog does something desirable, it is rewarded (positive reinforcement). When the dog does not, it receives no reward. Over time, the dog learns which behaviours lead to rewards.
The “agent” in AI is the model, which is trained to adjust its behaviour to maximise cumulative rewards over time.
What is RLHF in AI?
The concept of RLHF in AI is the integration of the strength of reinforcement learning with human judgment to produce more advanced models. Whereas conventional supervised learning trains models using fixed datasets, RLHF creates a continuous feedback mechanism in which human preferences actively influence the model's behaviour.
This becomes especially important in generative AI applications, in which subjective characteristics such as helpfulness, creativity, and safety are more important than basic accuracy measures.
It has been particularly relevant in training modern LLMs such as GPT-4 and Claude to produce responses that are natural and meet human expectations.
Who Invented RLHF?
Although there was no individual who invented RLHF, the method developed out of the work of various groups. Initial precursor work was done by researchers at OpenAI, DeepMind, and academic institutions who investigated the interaction between reinforcement learning and human preferences.
The 2017 article by Christiano et al., Deep Reinforcement Learning from Human Preferences, was a landmark in defining the fundamental methodology, although the technique has since undergone much improvement.
How Does RLHF Work?
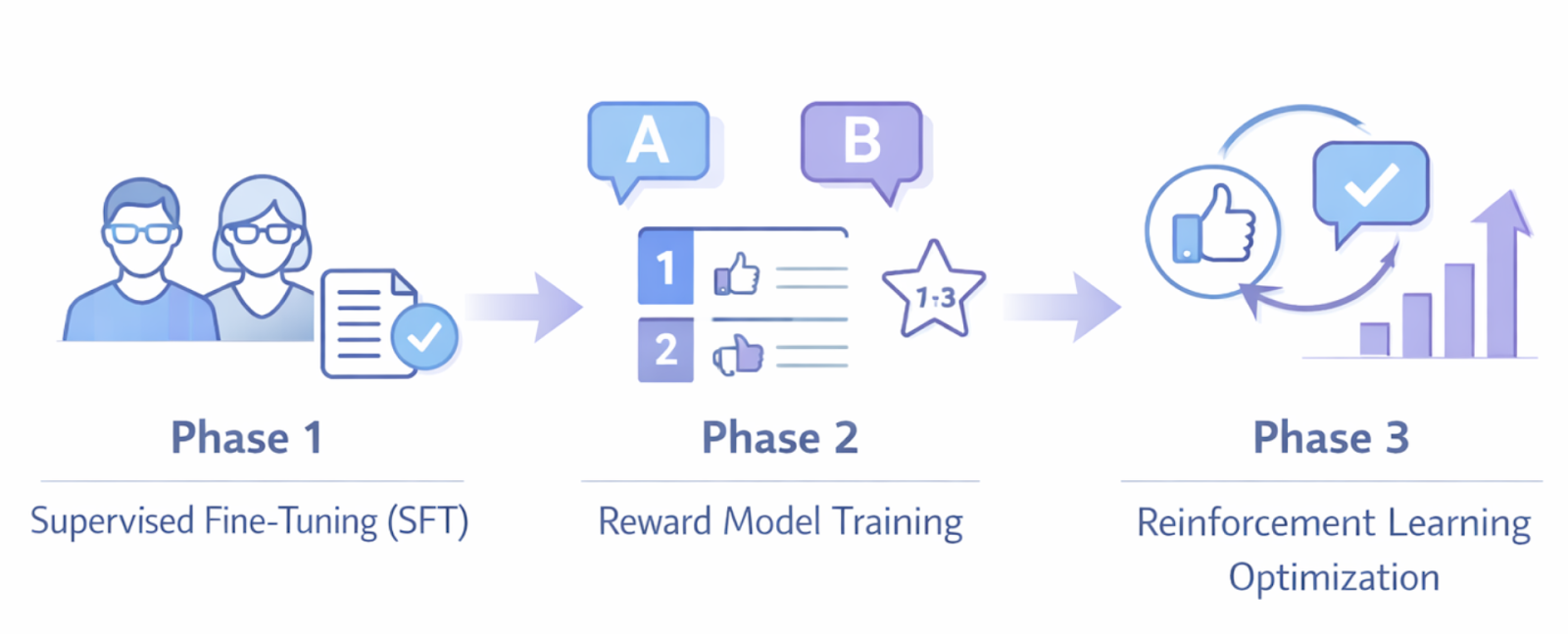
To understand the working process of RLHF, it is necessary to divide the process into three steps:
1. Supervised Fine-Tuning (SFT)
The journey begins with RLHF and SFT techniques working together. The first stage is to supervise fine-tuning the base language model; it is first trained using quality demonstration data.
Examples of desired outputs to different prompts are given by human experts, training the model on how to respond to different prompts. This initial stage lays the groundwork for competent behaviour.
2. Reward Model Training
Next comes the creation of a reward model in RLHF. Human evaluators compare several outputs of the models on the same prompt and rank them by quality, usefulness, and how they concur with the preferences of human beings. The rankings are then used to teach another reward model to automatically learn to predict human preferences.
The reward model is simply a proxy of human judgment, where different responses are given scores according to the learned human preferences. This is vital since it will be impractical and costly to have humans assess all of the outputs on each and every training.
3. Reinforcement-based Learning Optimisation
Lastly, the language model is trained with reinforcement learning algorithms, which typically is Proximal Policy Optimisation (PPO). Response is generated by the model, reward model scores them, and the LLM modifies its parameters to maximise the reward scores.
This forms a feedback loop whereby the model constantly becomes increasingly better in producing outputs that are preferred by human beings.
RLHF Techniques and Fine-Tuning Methods
Several RLHF techniques and fine-tuning techniques for LLMs have emerged to address different challenges:
- Direct Preference Optimisation (DPO): A simplified approach that bypasses the explicit reward model
- Constitutional AI: Uses AI-generated principles alongside human feedback
- Iterative RLHF: Multiple rounds of feedback collection and model refinement
RLHF fine-tuning and RLHF LLM fine-tuning specifically refer to the process of adapting pre-trained models using these human-in-the-loop methods, making them more suitable for real-world applications.
RLHF in Generative AI and LLMs
The impact of RLHF in generative AI and RLHF for LLMs cannot be overstated. Before RLHF became standard practice, language models often produced technically correct but unhelpful, unsafe, or socially inappropriate responses. RLHF in LLM training addresses these issues by explicitly teaching models to prioritise human values.
Reinforcement feedback examples in practice include training models to refuse harmful requests, provide balanced perspectives on controversial topics, and admit uncertainty rather than confidently stating incorrect information.
The Future of RLHF Machine Learning
RLHF machine learning continues to evolve as researchers discover new ways to incorporate human feedback more efficiently. The issues at hand today are to minimise the number of human resources needed, overcome biases in human taste, and extrapolate the method to even larger models.
With AI systems being more competent and integrated into society, RLHF has become necessary to make sure that these systems are of good service to human interests and are safe to use.
Conclusion
Understanding What RLHF in AI is reveals why modern language models are so remarkably capable. By combining human judgment with reinforcement learning, RLHF bridges the gap between raw computational power and nuanced human values.
Whether you're a developer implementing these systems or simply curious about AI advancement, RLHF represents one of the most important innovations in making artificial intelligence truly useful and aligned with human needs.
Explore Related Courses














COMMENTS(0)
Explore Related Courses
Our Popular Insights
Careers are shifting faster than ever, and staying relevant takes more than experience. Explore UniAthena’s most-read blogs for sharp insights, emerging skills, and practical pathways that help you move forward with clarity and confidence in a changing professional world.


What is Business Development?
Read More
6
mins read

🌟 Top Project Performer – June 2026 🌟
Read More
1
mins read

What is the Role of AI in Education?
Read More
4
mins read


🌟 Top Project Performer – May 2026 🌟
Read More
1
mins read


🌟 Top Project Performer – April 2026 🌟
Read More
1
mins read
What is Business Development?
Read more
6
mins read
🌟 Top Project Performer – June 2026 🌟
Read more
1
mins read
What is the Role of AI in Education?
Read more
4
mins read
🌟 Top Project Performer – May 2026 🌟
Read more
1
mins read

🌟 Top Project Performer – April 2026 🌟
Read more
1
mins read
Get in Touch

It’s Time to Start
Join NowMost Popular Online Specialization
- Master of International Business Administration
- Master of Business Administration
- MBA in General Management- FastTrack
- Master in Innovation and Entrepreneurship
- MBA-Family Business Management
- Master in Procurement and Contract Management
- Extended Diploma in Business Analytics (SCQF Level 11)
- Diploma in Supply Chain and Logistics Management (SCQF Level 11)
- Strategic Human Resource Management Practitioner
- Master in Data Science
- Master in Engineering Management
Trending Online
- Integrated Doctorate of Business Administration
- Postgraduate Certificate in Finance for Next Generation Managers
- Master of Business Administration- General Management (Fast Track)
- Postgraduate Certificate in Socio-Economic and Legal Framework
- Postgraduate Certificate in Business Sustainability
- Certified Manager
- Supply Chain Management Practitioner
- MBA - AI in Business
- MBA - Accounting & Finance
- Master in Supply Chain and Logistics Management
Top Universities Online Certificates
- Postgraduate Certificate in International Marketing Management
- Postgraduate Certificate In International Human Resource Management
- Postgraduate Certificate in Strategic Management
- Postgraduate Certificate in Procurement & Contracts Management
- Postgraduate Certificate in Business Analytics
- Postgraduate Certificate in Strategic Supply Chain & Logistics Management
- Postgraduate Certificate in Human Resource and Leadership
- Project Management Practitioner
- Postgraduate Certificate in Supply Chain Design & Implementation
- Postgraduate Certificate in Management Accounting and Finance
Accredited Online Degree Program
- MBA - Digital Transformation
- MBA - Family Business Management
- MBA - Marketing Management
- MBA in Quality Management
- MBA - Business Intelligence & Data Analytics
- MBA in Operations & Project Management
- MBA in Energy Management
- MBA In Construction & Safety Management
- Master in Organisational Leadership
- Master in Public Health
- Master in Construction Management
- Bachelor of Arts in Business Administration



UniAthena is an Ed-Tech, offering flexible, affordable learning solutions, including Free-Learning Upskilling Courses and Academic Programs in partnerships with accredited and globally renowned universities and professional qualification bodies.




Do you have any questions ?
Feel free to send us your questions or request a free consultation
Send a messageUK
Athena Global Education
Magdalen Centre,
Robert Robinson Avenue,
Oxford, OX4 4GA, UK
Phone : 01865 784299
MIDDLE EAST
Athena Global Education FZE
Block L-03, First Floor,
P O Box 519265, Sharjah Publishing City,
Free Zone, Sharjah, UAE
Phone : +971 55 879 5492
INDIA
Uniathena Private Limited
9A,Midas Tower
Phase 1
Hinjewadi Rajiv Gandhi Infotech Park
Pune-411057
Phone: +91 9145665544
All Copyrights Reserved @ Athena Global Education 2021-2026