-

Bachelor's

-

Masters
-

MBA
-

Doctorate
-

Micro Credit
-

Explore all Courses
-
Postgraduate Certifications

-
Postgraduate Diploma
-
Undergraduate Diploma
-
Diploma







A 2.85× Leap in Real-Time AI Efficiency: The VL-JEPA Breakthrough

Author: pallavi patnaik
|8
MINS READ
| 0
| 306
Created On: 17 March, 2026
Share





Table of Contents (TOC):
- Introduction
- Key Takeaways
- The Efficiency Problem in Modern AI Systems
- What is VL-JEPA? Understanding the Vision-Language Joint Embedding Architecture
- How VL-JEPA Achieves 2.85× AI Performance Improvement
- Where the 2.85× Efficiency Gain Comes From
- Performance Benchmarks: VL-JEPA vs Traditional Vision-Language Models
- Real-World Applications of VL-JEPA
- Why VL-JEPA Matters for the Future of AI
- Conclusion
- FAQs
Introduction
Imagine a technician wearing smart glasses while repairing a complex machine on a factory floor. As they look at different components, the glasses instantly recognize parts, provide instructions, and warn about potential errors. The experience feels seamless, almost like having a knowledgeable assistant watching the world alongside you.
But behind this seemingly effortless interaction lies a difficult engineering challenge. For AI systems to interpret images, understand language, and respond in real time, they must process massive amounts of data extremely quickly. Traditional AI models often struggle to keep up with this demand because they generate responses step by step, which introduces delays and increases computational cost.
As real-time applications expand across robotics, augmented reality, and autonomous systems, the need for faster and more computationally efficient multimodal AI architectures has become increasingly clear.
This is where VL-JEPA (Vision-Language Joint Embedding Predictive Architecture) enters the conversation. Developed as a new approach to vision-language learning, VL-JEPA moves away from traditional token-based generation and instead predicts semantic embeddings. This design enables the model to process information more efficiently while maintaining strong performance across multiple tasks.
One of the most notable outcomes of this approach is a 2.85× reduction in decoding operations during inference, allowing AI systems to operate more efficiently in real-time environments.
For organizations building next-generation AI systems, VL-JEPA offers an important glimpse into how future models may balance performance, scalability, and computational efficiency.
Key Takeaways:
- VL-JEPA introduces a new architecture for vision-language architecture that predicts semantic embeddings instead of generating tokens sequentially.
- The model reduces decoding operations by approximately 2.85×, improving efficiency in real-time applications.
- VL-JEPA achieves strong performance with about half the trainable parameters compared to many traditional vision-language models.
- A single architecture can handle multiple tasks, including classification, captioning, retrieval, and visual question answering.
- The approach is particularly suited for streaming video analysis, robotics, and interactive AI systems.
The Efficiency Problem in Modern AI Systems
Over the past few years, vision-language models (VLMs) have become central to many AI applications. These systems can analyze images or videos while understanding natural language prompts.
However, most of these models rely on autoregressive text generation. In simple terms, they produce responses one token at a time. While this approach works well for generating detailed text, it introduces several challenges.
1. Sequential Generation Creates Latency
When a model generates text token by token, it cannot finalize a response until the entire sequence is produced. This slows down systems that require immediate responses.
For example, in a real-time video monitoring system, the model may need to continuously interpret new frames. If it must generate long textual responses each time, delays become unavoidable.
2. High Computational Costs
Token-based generation requires significant computing resources. Large models must perform repeated decoding operations, which increases processing time and energy consumption.
This becomes a serious limitation for applications running on edge devices, wearable technology, robotics systems, and mobile platforms.
3. Difficulty Handling Continuous Data Streams
Applications involving live video or sensor data require AI systems to constantly update their understanding of the environment. Traditional models often struggle in such scenarios because they must repeatedly perform expensive decoding steps.
These challenges highlight a fundamental question: Can AI models understand meaning without generating every word explicitly?
VL-JEPA attempts to answer that question.
What is VL-JEPA? Understanding the Vision-Language Joint Embedding Architecture
VL-JEPA is built on the concept of Joint Embedding Predictive Architecture (JEPA). Instead of predicting text tokens directly, the model learns to predict semantic representations of responses in an embedding space.
This shift allows the model to focus on meaning rather than the exact wording of an answer.
For instance, consider the following two responses to the same visual scene:
- “The room becomes dark.”
- “The lamp turns off.”
Although the wording is different, both responses convey a similar meaning. In a traditional token-based model, these responses appear very different because they use different words. In an embedding-based approach, however, both answers can be represented as nearby points within semantic space.
This simplifies the learning problem and allows the model to focus on task-relevant meaning rather than linguistic variations.
The result is a system that can maintain strong performance while reducing computational overhead.
Also Read: From APIs to MCP: How AI Integration is Being Rewritten
How VL-JEPA Achieves 2.85× AI Performance Improvement
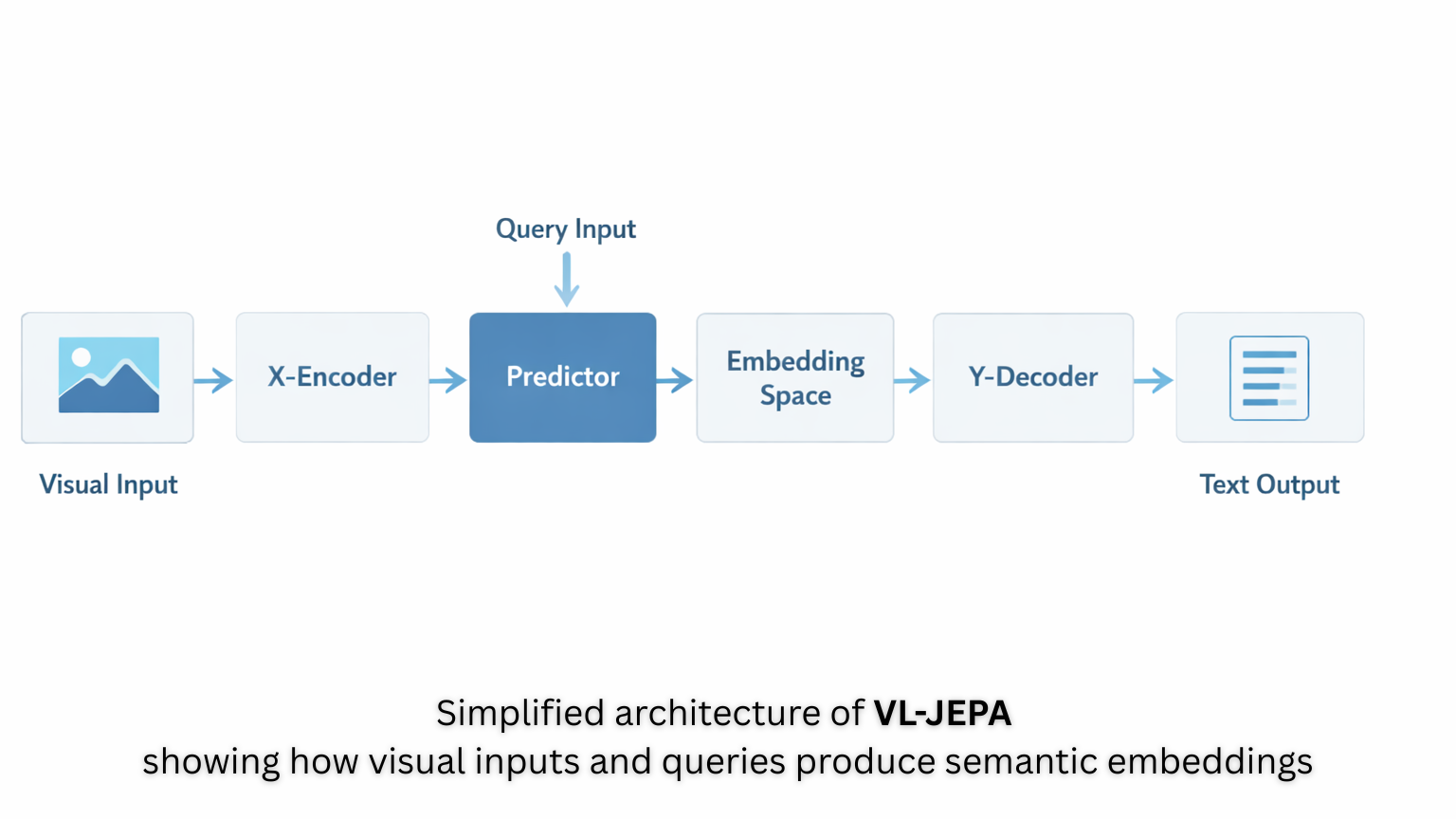
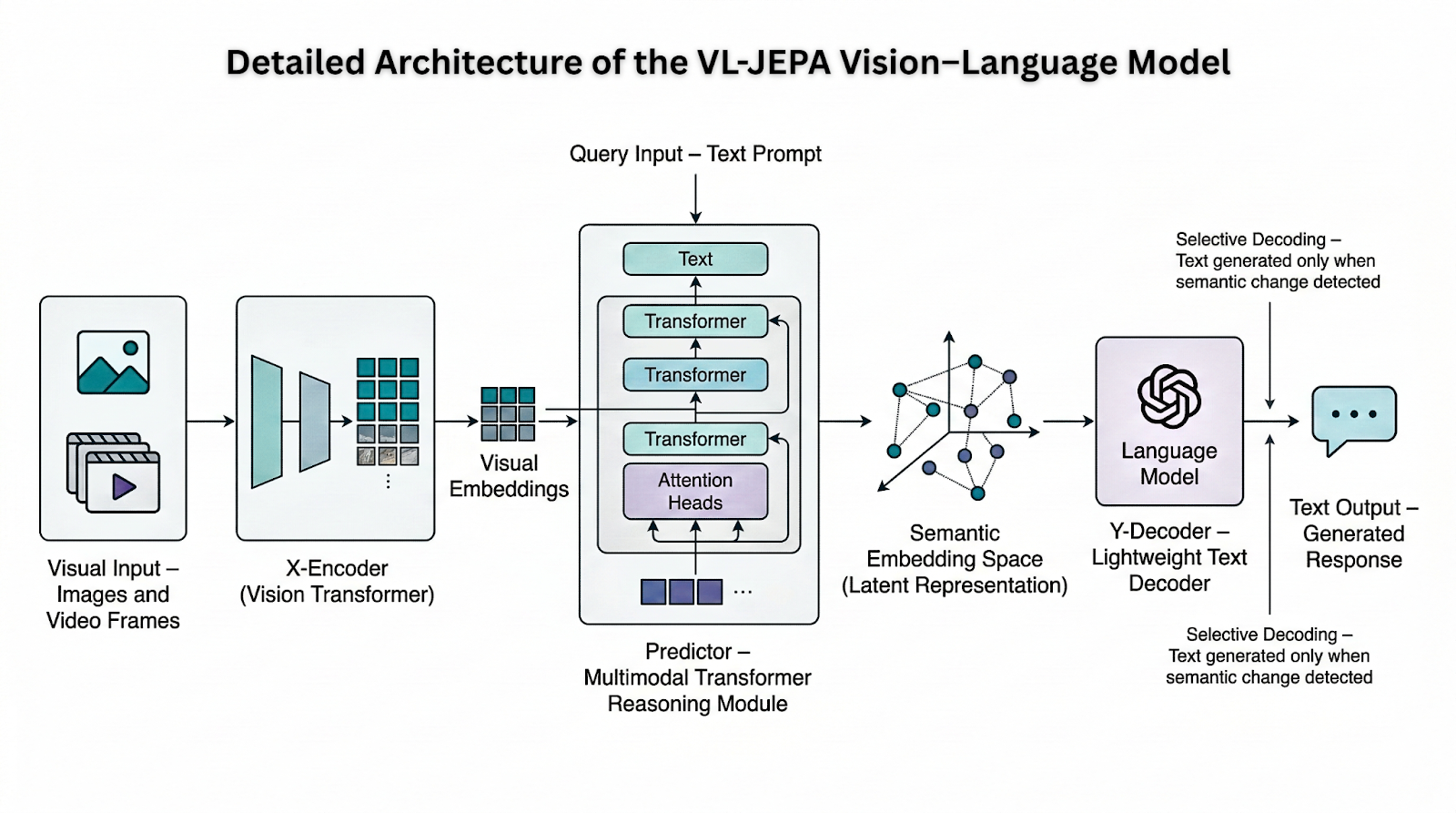
VL-JEPA is composed of four main components that work together to process visual and textual information. This architecture allows VL-JEPA to process visual information continuously while generating text selectively.
1. X-Encoder
The X-Encoder processes visual inputs such as images or video frames and converts them into compact embeddings. These embeddings capture essential visual features while reducing the amount of data the model needs to handle.
2. Predictor
The Predictor acts as the core reasoning component of the model. It combines visual embeddings with the user’s query and predicts the semantic embedding representing the expected answer.
3. Y-Encoder
The Y-Encoder converts target text into embeddings during training. This allows the model to compare predicted semantic representations with the correct answer.
4. Y-Decoder
The Y-Decoder converts predicted embeddings into human-readable text when necessary. Importantly, the decoder is used only when a textual response is required, which reduces computational overhead.
Where the 2.85× Efficiency Gain Comes From
One of the most significant innovations in VL-JEPA is a technique called selective decoding.
In traditional systems, decoding happens continuously. Every step of processing requires text generation, even when the underlying meaning has not changed.
VL-JEPA takes a different approach. Instead of decoding every prediction, the model monitors the semantic embedding stream. Text is generated only when a meaningful change occurs in the predicted representation. Researchers tested this method on long video streams. The results showed that selective decoding could maintain comparable output quality while reducing the number of decoding operations by approximately 2.85×. This improvement significantly reduces computational cost while maintaining performance.

Also Read: What is an AI Agent? Simple Explanation for Beginners
Performance Benchmarks: VL-JEPA vs Traditional Vision-Language Models
To evaluate its effectiveness, VL-JEPA was tested across multiple tasks and datasets, where the results demonstrated strong performance in areas such as zero-shot classification, text-to-video retrieval, and visual question answering.
In controlled experiments, the model achieved higher average classification accuracy and retrieval performance compared with several baseline models, including CLIP and SigLIP2.
Another notable advantage is its efficiency, as VL-JEPA delivers competitive results while using roughly half the number of trainable parameters required by many conventional vision-language systems. This balance between strong performance and improved efficiency makes the architecture particularly valuable for real-time AI applications.
Real-World Applications of VL-JEPA
The architectural advantages of VL-JEPA make it suitable for several emerging AI use cases.
1. Real-Time Video Understanding
Streaming video platforms and surveillance systems require fast interpretation of visual data. VL-JEPA’s selective decoding enables efficient processing of long video streams.
2. Smart Wearables and Augmented Reality
Devices such as smart glasses need instant contextual understanding without relying on heavy cloud processing. Efficient multimodal models can make these devices more responsive.
3. Robotics and Automation
Robots operating in dynamic environments must constantly interpret visual inputs and respond quickly. VL-JEPA’s architecture supports continuous perception with lower latency.
4. Interactive AI Systems
AI assistants that combine visual and language understanding can benefit from faster inference and lower computational requirements.
Also Read: Cloud-Native AI: Building ML Models with Kubernetes and Microservices
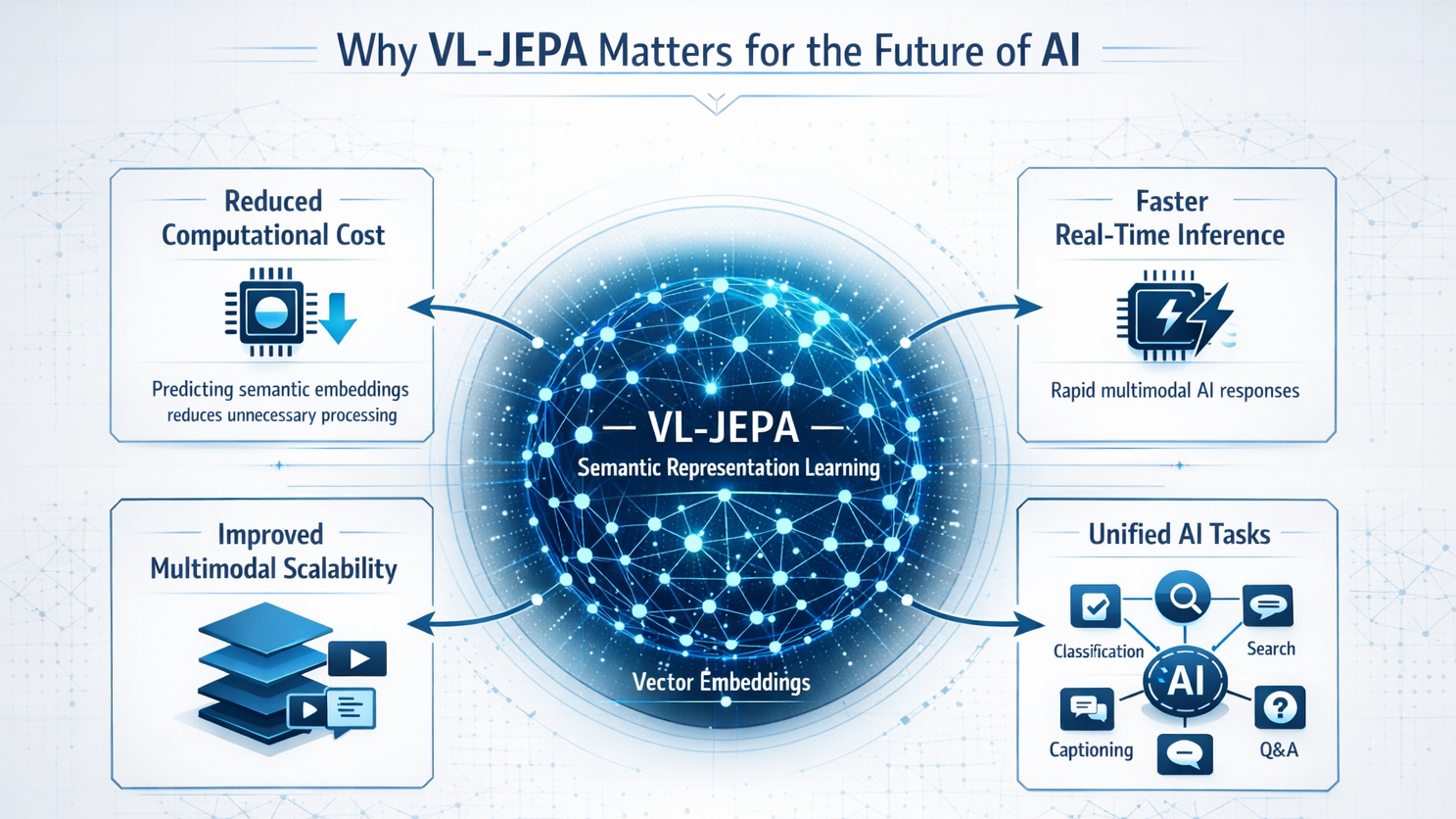
Why VL-JEPA Matters for the Future of AI
VL-JEPA highlights an important shift in AI research: moving from token-level prediction to semantic representation learning. This approach provides several long-term benefits:
- Reduced Computational Cost: By predicting semantic embeddings instead of generating tokens step by step, VL-JEPA minimizes unnecessary processing and significantly lowers the overall computational workload.
- Faster Real-Time Inference: The model processes visual and language information more efficiently, enabling quicker responses that are crucial for real-time applications such as video analysis and robotics.
- Improved Scalability for Multimodal Systems: VL-JEPA’s architecture can handle large volumes of image, video, and text data more effectively, making it easier to scale AI systems across complex multimodal environments.
- Better Integration Across Multiple AI Tasks: A single VL-JEPA framework can support various tasks—such as classification, retrieval, captioning, and question answering—without requiring separate specialized models.
As AI continues to expand into real-world environments such as autonomous systems, wearable devices, and industrial automation, architectures designed for efficiency will become increasingly important. VL-JEPA demonstrates how focusing on semantic representations can unlock new levels of performance while reducing resource demands.
Conclusion
As AI systems increasingly move into real-world environments, achieving real-time AI efficiency has become a critical requirement. Applications such as robotics, augmented reality, and autonomous systems demand models that can process visual and language data quickly while minimizing computational costs.
The VL-JEPA breakthrough addresses this challenge by introducing a vision-language joint embedding architecture that focuses on semantic prediction rather than token generation.
Through innovations such as selective decoding, the model achieves a remarkable 2.85× AI performance improvement, enabling faster inference, reduced latency, and improved AI compute efficiency.
This multimodal AI breakthrough demonstrates how future high-performance AI models may balance scalability, efficiency, and real-time performance. As research continues to explore embedding-based architectures, approaches like VL-JEPA may play a key role in the next generation of intelligent systems.
Also Read: How Much Can AI Really Remember? Inside the LLM Context Window
FAQs
Q1. What is VL-JEPA in AI?
A: VL-JEPA is a vision-language model architecture that predicts semantic embeddings rather than generating text token by token.
Q2. Why is VL-JEPA more efficient than traditional models?
A: It uses a technique called selective decoding, which generates text only when meaningful semantic changes occur.
Q3. What does the 2.85× improvement represent?
A: It refers to the reduction in decoding operations during inference while maintaining comparable performance levels.
Q4. What tasks can VL-JEPA perform?
A: The model supports classification, captioning, retrieval, and visual question answering within a single architecture.
Q5. Why is this research important?
A: VL-JEPA demonstrates a new direction for building efficient multimodal AI systems capable of operating in real-time environments.
Explore Related Courses














COMMENTS(0)
Explore Related Courses
Our Popular Insights
Careers are shifting faster than ever, and staying relevant takes more than experience. Explore UniAthena’s most-read blogs for sharp insights, emerging skills, and practical pathways that help you move forward with clarity and confidence in a changing professional world.


🌟 Top Project Performer – June 2026 🌟
Read More
1
mins read



🌟 Top Project Performer – May 2026 🌟
Read More
1
mins read



🌟 Top Project Performer – April 2026 🌟
Read More
1
mins read

🌟 Top Project Performer – June 2026 🌟
Read more
1
mins read
🌟 Top Project Performer – May 2026 🌟
Read more
1
mins read
🌟 Top Project Performer – April 2026 🌟
Read more
1
mins read
Get in Touch

It’s Time to Start
Join NowMost Popular Online Specialization
- Master of International Business Administration
- Master of Business Administration
- MBA in General Management- FastTrack
- Master in Innovation and Entrepreneurship
- MBA-Family Business Management
- Master in Procurement and Contract Management
- Extended Diploma in Business Analytics (SCQF Level 11)
- Diploma in Supply Chain and Logistics Management (SCQF Level 11)
- Strategic Human Resource Management Practitioner
- Master in Data Science
- Master in Engineering Management
Trending Online
- Integrated Doctorate of Business Administration
- Postgraduate Certificate in Finance for Next Generation Managers
- Master of Business Administration- General Management (Fast Track)
- Postgraduate Certificate in Socio-Economic and Legal Framework
- Postgraduate Certificate in Business Sustainability
- Certified Manager
- Supply Chain Management Practitioner
- MBA - AI in Business
- MBA - Accounting & Finance
- Master in Supply Chain and Logistics Management
Top Universities Online Certificates
- Postgraduate Certificate in International Marketing Management
- Postgraduate Certificate In International Human Resource Management
- Postgraduate Certificate in Strategic Management
- Postgraduate Certificate in Procurement & Contracts Management
- Postgraduate Certificate in Business Analytics
- Postgraduate Certificate in Strategic Supply Chain & Logistics Management
- Postgraduate Certificate in Human Resource and Leadership
- Project Management Practitioner
- Postgraduate Certificate in Supply Chain Design & Implementation
- Postgraduate Certificate in Management Accounting and Finance
Accredited Online Degree Program
- MBA - Digital Transformation
- MBA - Family Business Management
- MBA - Marketing Management
- MBA in Quality Management
- MBA - Business Intelligence & Data Analytics
- MBA in Operations & Project Management
- MBA in Energy Management
- MBA In Construction & Safety Management
- Master in Organisational Leadership
- Master in Public Health
- Master in Construction Management
- Bachelor of Arts in Business Administration



UniAthena is an Ed-Tech, offering flexible, affordable learning solutions, including Free-Learning Upskilling Courses and Academic Programs in partnerships with accredited and globally renowned universities and professional qualification bodies.




Do you have any questions ?
Feel free to send us your questions or request a free consultation
Send a messageUK
Athena Global Education
Magdalen Centre,
Robert Robinson Avenue,
Oxford, OX4 4GA, UK
Phone : 01865 784299
MIDDLE EAST
Athena Global Education FZE
Block L-03, First Floor,
P O Box 519265, Sharjah Publishing City,
Free Zone, Sharjah, UAE
Phone : +971 55 879 5492
INDIA
Uniathena Private Limited
9A,Midas Tower
Phase 1
Hinjewadi Rajiv Gandhi Infotech Park
Pune-411057
Phone: +91 9145665544
All Copyrights Reserved @ Athena Global Education 2021-2026